Gerek Kariyer.net gerek diğer birçok kurumsal firmada yöneticiler çalışanlarından dönemsel/konu odaklı raporlar istemektedir. Bu talepler çoğu zaman mail üzerinden gelirken kimi zaman da sözlü olarak ifade edilmektedir. Talebin, çalışan tarafından doğru bir şekilde anlaşılması ve raporlanması zaman alabildiği gibi kimi zaman da doğru raporlanması mümkün olmamaktadır.
Projemizde, kurum ve yönetici parametrelerini dikkate alarak geçmiş raporlarda yapılan değerlendirmeler de göz önünde bulundurulup verilerin en doğru biçimde raporlanması amaçlanmıştır. Bu noktada sistemde geçmiş raporlardaki değerlendirmelerden yararlanılması başarıyı ve faydayı arttıran önemli bir faktördür. Bunun önemini şu şekilde açıklayabiliriz; bir yönetici daha önce bir çok kez rapor istediği çalışanı ile rapor ekibine yeni gelen bir arkadaştan aynı raporu istediğini düşünelim. Raporu isteme biçimi, verdiği detaylar ve alacağı sonuç kuşkusuz farklı olacaktır. Bu ihtiyaçları da hesaba katarak biz de süreci otomatize ederek yönetici ile doğrudan bağlam temelli ve doğal dil etkileşimli bir raporlama asistanı geliştirmek istedik.
Peki piyasada kullanılabilecek raporlama araçları ve sesli asistanlar varken neden yeni bir sistem geliştirme ihtiyacı duyduk?
Öncelikle yöneticilerin mevcut raporlama araçları ile direkt etkileşim halinde olabilmeleri için o toola ait bilgi ve zamana ihtiyaçları var. Yöneticinin istediği bu değil ama. Yönetici talebinin hazır olarak elinde olmasını ister. Bunun için bu tooları kullanan çalışanlardan talep etmekte. Geliştiridiğimiz sistem ile artık direkt olarak doğal dil ile etkileşim halinde olacak ve anlık raporları alabilecek. Yani günlük konuşma dilinde bir çalışanında nasıl rapor talep ediyorsa aynı şekilde sistemden bir rapor talebinde bulunabilecek.
Peki böyle sistemler yok mu?
Benzer özelliklere sahip uluslar arası kullanılabilecek böyle sistemler var fakat Türkçe desteği yeterli değil. Türkçe için ise kullanılabilecek hazır bir sistem yok. Çünkü Türkçe yapısı gereği zor bir dil ve böyle bir sistem yapmak istediğimizde ilk olarak dilin yapısındaki zorluklar karşımıza çıkmakta. Türkçenin sondan eklemeli bir dil oluşu, kökeni aynı olan kelimelerin aldığı ekler ile birçok farklı anlama gelmesi Türkçe cümlelerin anlaşılmasını zorlaştıran nedenler.
Türkçe'nin dil yapısının getirdiği bu zorluklarla uğraşmak istemeyip zaten halihazırda kullanılan İngilizce kullanıma yönelik sunulan sistemleri kullanmak istediğimizde ise Türkçe -İngilizce şeklinde çeviriler yaparak kullanmak mümkün fakat bu noktada da çeviri sırasında bilgi kayıpları olması,istenilen kalıpların çıkarımının zor olması ve çevirinin her zaman başarılı gerçekleşmemesi sonucu bu sistemler verimli olamamakta, bize ideal çözümü vermemektedir. Türkçe için kullanılacak bir sisteme duyduğumuz ihtiyaçları bu şekilde özetleyebiliriz.
 Projenin ön hazırlık aşaması olarak talep cümlelerinin rapor parçalarına ayrıştırılabilmesi için cümledeki kelimelerin morfolojik yapıları çıkartılmıştır. Rapor talep cümlelerinin dar kapsamında geçerli olacak şekilde, morfolojik yapıların birbirini takip etme kuralları çıkartılmış ve bu kurallara göre morfoloji seçimi gerçekleştirilmiştir. (Morfoloji, dilde biçimi oluşturan ögelerin türlerini tanımlamak ve dil bilgisi kuralları denen biçimsel ögelerin sınıflandırmasını şeklinde özetlenebilir)
Projenin ön hazırlık aşaması olarak talep cümlelerinin rapor parçalarına ayrıştırılabilmesi için cümledeki kelimelerin morfolojik yapıları çıkartılmıştır. Rapor talep cümlelerinin dar kapsamında geçerli olacak şekilde, morfolojik yapıların birbirini takip etme kuralları çıkartılmış ve bu kurallara göre morfoloji seçimi gerçekleştirilmiştir. (Morfoloji, dilde biçimi oluşturan ögelerin türlerini tanımlamak ve dil bilgisi kuralları denen biçimsel ögelerin sınıflandırmasını şeklinde özetlenebilir)
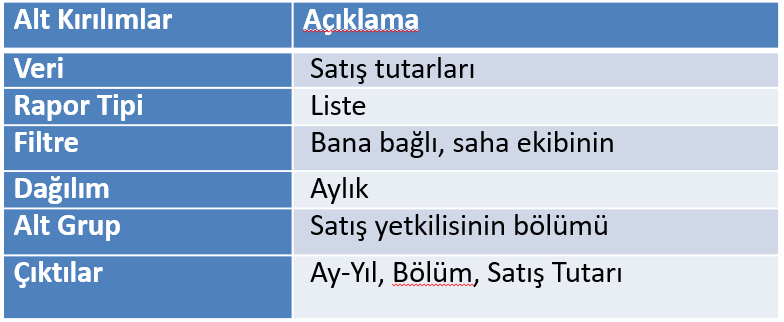
Bir rapor talebi cümlesi, özellikle çok uzun ve karışık bir hale getirilmediği sürece, makul kullanım ihtiyaçları içerisinde altı farklı parçadan meydana gelmektedir Burada bir örnek vermek gerekirse;
“Bana bağlı saha ekibinin aylık satış tutarlarının, satış yetkilisinin departmanı bazlı listesi” talebinin parçaları aşağıdaki gibi olacaktır:
Basit bir rapor cümlesinin parçaları bu şekilde listelenebilir ancak rapor talepleri aynı zamanda bu listede görünmeyen, açıkça belirtilmemiş gizli filtreler ve çıktılar içerebilir. İncelediğimiz örnekte de açıkça belirtilmese de satış rakamları, içinde bulunulan yıl için istenmektedir. Yani talebimiz aslında
“Bana bağlı saha ekibinin bu yılki aylık satış tutarlarının, satış yetkilisinin departmanı bazlı listesi” şeklindedir.
Raporun bağlamına göre bu çıkarımların yapılması raporlama sisteminin kullanıcı gözündeki başarısını yükselten bir etmen olacağı için gizli filtre ve çıktıların belirlenebilmesi önemli bir adımdır.
Bir diğer dikkat edilmesi gereken husus da bağlılık analizidir. Bağlılık analizi (dependency parsing) türkçenin yapısı nedeniyle genel çözümü zor bir problem olmaktadır. Türkçede cümlenin parçalarının sırası değişebilir.Örneğin;
“Bana bağlı saha satış ekibi yetkililerinin, hedef tipi kırılımında aylık toplam satış tutarları nelerdir” cümlesini
“Bana bağlı saha satış ekibi yetkililerinin, aylık toplam satış tutarları hedef tipi kırılımında nedir” şeklinde kullanmak tamamen doğru ve anlaşılır bir kullanım şeklidir.
Cümlenin rapor parçalarına ayrıştırılması için “cümle parçalarını işaretleme” (pos tagging) çalışmalarına başlanmıştır. Burada gerçekleştirdiğimiz iki önemli alt rutin bulunmaktadır;
“ve / veya / virgül” kullanımı da cümlenin bazı parçalarının birlikte kullanılmasını sağladığı için anlamsal olarak genişletilmesi gereken durumların belirlenmesi
Zaman veya dönem gösteren parçaların bulunması için bir “zaman zarfı” belirlenmesi
Örnek olarak
“Bana bağlı yenileme ekibi yetkilileri tarafından son 1 ay içerisinde teklif verilmemiş ve aranmamış olan firmalar listesi” cümlesinde “aranmamış” eyleminin de “son 1 ay içerisinde” gerçekleşmesi gerekmektedir. Analizi yapan sistemin anlamı kaybetmemek ve doğru parçaları bulmak adına yukarıda bahsettiğimiz ilk durumu gözetmesi gerekir.
Cümlenin parçalara ayrılması sonucunda elde edilen sonuç aşağıdaki gibidir.
Hiyerarşik yerleşim parçaların birbirine nasıl bağlandığını göstermektedir. Bir sonraki adımda “ve” ile ayrılan parçalar birbirlerine alt hiyerarşilerini aktarırlar. Yani yapı aşağıda gösterildiği gibi olmaktadır.
Bu parçalar içerisinden rapor için gerekli yapılar çıkarıldığında ise sonuç aşağıdaki tabloda verildiği gibi olmaktadır.

Yukarıda bahsedilen ikinci alt rutin kullanılarak “Son 1 ay” vb. şeklinde belirtilen zaman dilimlerinin tam karşılığının bulunması için aşağıdaki dönüşüm örnekleri verilebilir;
|
Son 1 ay
|
15.11.2018 – 15.12.2018 arası |
| Henüz |
Bugünden (15.12.2018) öncesi |
| 1 yıldır |
15.12.2017 – 15.12.2018 |
| 2 gündür |
13.12.2018 den sonra |
Yukarıda bahsedilen bir rapordan kelime gruplarının, zaman kalıplarının ve sorguya verilecek koşulların çıkarılmasını inceledik fakat geliştirilen bu yapı mevcutta kullanılan veri saklama yöntemleri üzerinden (ilişkisel veri tabanı) sorgulama yapmak için maalesef hala yeterli değil. Çünkü saklanılan veri birçok veritabanında dağınık halde ve istenilen filtrenin, dağılımın ve alt grubun hangi veri tabanında hangi tabloda olduğu bilgisine sahip olmak ve bunlara sorgu sırasında erişmek oldukça maliyetli.
Bu amaçla test ortamı için kullanılacak verinin bir kısmı ilişkisel SQL veritabanından çekilerek 3’lü gösterim formatına dönüştürülmüş ve triplestore a aktarılmıştır. TripleStore sistemleri çizge sorgulaması yapmaya imkan veren yapılardır. Basit olarak nitelendirilebilecek üçlü formatta (subject – predicate – object) verilerin ontolojik olarak kayıt edilmesine ve SPARQL dili kullanarak sorgulanmasına izin verirler.
“Bana bağlı saha ekibinin aylık satış tutarlarının, satış yetkilisinin departmanı bazlı listesi”
talebine geri dönecek olursak SPARQL sorgusuna dönüşümü sağ görülebilir.
Kullanıcıdan gelen talebin ayrıştırılması sonrası raporda istenen veriyi bulmak için uygun sorgu oluşturulacak ve veri kaynağından talep edilecektir. Talepten anlaşılan rapor tipine göre (liste / bar grafik / skaler değer) gelen verinden raporun oluşturulması için chart.js kütüphanesi kullanılmaktadır. Aynı grafik üzerinden birden fazla veri setinin gösterilmesi ihtiyacı bu kütüphane ile sağlanabilmektedir.
Oluşturulan rapor, web sayfası, pdf veya powerpoint slayt olarak raporu talep eden kişiye ulaştırılır.