2014 yılında Kariyer.net sistemine entegre ettiğimiz ve Ekspres Cv adını verdiğimiz Tübitak Destekli projemiz için neler yaptık, hangi sorunlarla uğraştık ve sonuçta ortaya ne çıktı anlatalım istedik.
 Mutlaka hayatınızın bir anında "CV_ORNEGI.doc" isimli bir word dökümanla haşır neşir olup kendi özgeçmişinizi oluşturmak zorunda kalmışsınızdır. Yapıp, heh valla güzel oldu, dedikten sonra ise başkalarının hazırladıkları özgeçmişleri görüp, kendi yaptığınızın yeterli olmadığını hissetmişsinizdir. Çünkü dünyada binlerce farklı cv formatı var ve bunları doldurmanın da yine binlerce farklı yolu. Bu hem özgeçmiş hazırlama süreceni, hem bu özgeçmişlerin değerlendirilmesini olumsuz etkileyen bir durumdur.Bunun yanında Kariyer.net bazlı bir sistemde aranabilir hale gelmeniz için özgeçmişinizi sistemin istediği formatta girmeniz gerekmektedir.
Mutlaka hayatınızın bir anında "CV_ORNEGI.doc" isimli bir word dökümanla haşır neşir olup kendi özgeçmişinizi oluşturmak zorunda kalmışsınızdır. Yapıp, heh valla güzel oldu, dedikten sonra ise başkalarının hazırladıkları özgeçmişleri görüp, kendi yaptığınızın yeterli olmadığını hissetmişsinizdir. Çünkü dünyada binlerce farklı cv formatı var ve bunları doldurmanın da yine binlerce farklı yolu. Bu hem özgeçmiş hazırlama süreceni, hem bu özgeçmişlerin değerlendirilmesini olumsuz etkileyen bir durumdur.Bunun yanında Kariyer.net bazlı bir sistemde aranabilir hale gelmeniz için özgeçmişinizi sistemin istediği formatta girmeniz gerekmektedir.
Bu süreç bu projenin tam olarak doğuş nedeni.
Proje ile amacımız da:
Türkçe yazılmış yapısal olmayan özgeçmişlerin metin kısmında bulunan kişisel bilgiler, genel bilgiler, eğitim bilgileri (lise, üniversite adı, fakülte ve bölümü), yetkinlikler, sertifikalar, projeler, yabancı dil bilgisi, iş tecrübesi bilgisi (şirket adı, pozisyon, sektör ve iş açıklaması), referanslar ve ek bilgiler bilgilerinin çıkarımını gerçekleştirip, Kariyer.net in cv sistemi yapısına çevirmekti..
Metodoloji
Word dökümanlarının iç yapısının anlaşılması zor karakterler içermesinden ve etiket yapısı olmamasından dolayı, özgeçmişler anlaşılması ve incelenmesi daha iyi olan ve belirli bir etiket yapısına sahip olan HTML yapısına çevirme işlemleriyle başladık.
HTML yapısına çevrilmiş düz metin içerisinden paragraf ve cümleler oluşturarak, çıkardığımız bilgileri Kariyer.net Özgeçmiş Ontolojisine ekledik. Özgeçmiş Ontolojisindeki bilgileri işlemek için OWL API2 (Ontoloji derleyici) kullandık. Sonrasında yen kavramlar çıkarmak için Semantik Web Kural Dili (SWRL) kullanarak kurallar yazdık.
Morfolojik Analiz
Yukarıdaki yöntemlerle yaş, adres, eğitim, yabancı dil gibi bilgileri herhangi bir formatta serbest yazılmış bir özgeçmişten çıkardık. En zor kısmı en sona bıraktık. "İş Tecrübeleri"..
Hayat hikayesini anlatanlar, Türkçe imla kurallarını kullanmamaya yemin etmiş özgeçmişler ve daha nicelerinin derya olduğu, iş deneyimlerinizi anlatmanız için sınırınız olmayan bir text alanı. Buradan kişinin hangi pozisyonlarda çalıştığını, sektörlerini, kullandığı araçları ve tabi ki yetenekleri çıkarma işlemlerine başladık.
Bunu başarabilmek için metni morfolojik analizden geçirmeye başladık, ki bunu bir kelimenin yapısını (kelimenin kökü ve aldığı ekler) ortaya çıkarmak için yaptık. Türkçe gibi eklemeli dillerde, genellikle bir kelimeyi yazıldığı gibi almak yerine kelimenin kökünü tespit ederek kökü (ve gerekiyorsa ekleri) kullanmak daha başarılı sonuçlar vermektedir. Morfolojik analiz işleminden sonra ise morfolojik muğlaklık giderme (morphological disambiguation) işlemi gerçekleştirdik. Türkçe kelimelerin önemli bir bölümü birden çok anlama sahiptir. Bir dokümanda yer alan bir kelimenin, kullanıldığı bağlama (context) bakılarak doğru anlamının tespit edilmesi gerekmektedir. Bunu sağlayabilmek için Boğaziçi Üniversitesi tarafından geliştirilen morfolojik analiz ve muğlaklık giderici aracı kullandık ([13] Sak, H., Güngör, T. ve Saraçlar, M. “Resources for Turkish Morphological Processing”, Journal of Language Resources and Evaluation, Cilt 45, s. 249-261, 2011.).
Örnek bir iş tecrübesi ve morfolojik analiz sonucunu aşağıda görebilirsiniz.

Metni Anlama
Önceki çalışmalarla birlikte ilan metni çıkarma işlemleri yaptık.
Örneğin;
"En az 3 yıl proje müdürü olarak çalışmış ve çok iyi derecede Java bilen" cümlesinin bilgi çıkarımından elde edilen sonuç:
isYetkinlik(pozisyon(proje müdürü), yetkinlik(java), 3, çok iyi, yanlış)’dır.
Buradan sonra ki çalışmalarla aşağıda gördüğünüz resmi çizebildik yani başarılı bir biçimde, ilan metinlerinden herhangi bir pozisyonun istediği nitelikleri ve bunların birbiriyle ilişkisini bulabiliyoruz. Bilgi tabanımızı oluştururken Graph veritabanlarından olan AllegroGraph ı kullandık.. AllegroGraph bir kaynak tanımlama çerçevesi (resource definition framework) üçlü deposudur. AllegroGraph içerisinden bilgiyi sorgulamak ve elde etmek için SPARQL(protocol and RDF query language) dilini kullandık.
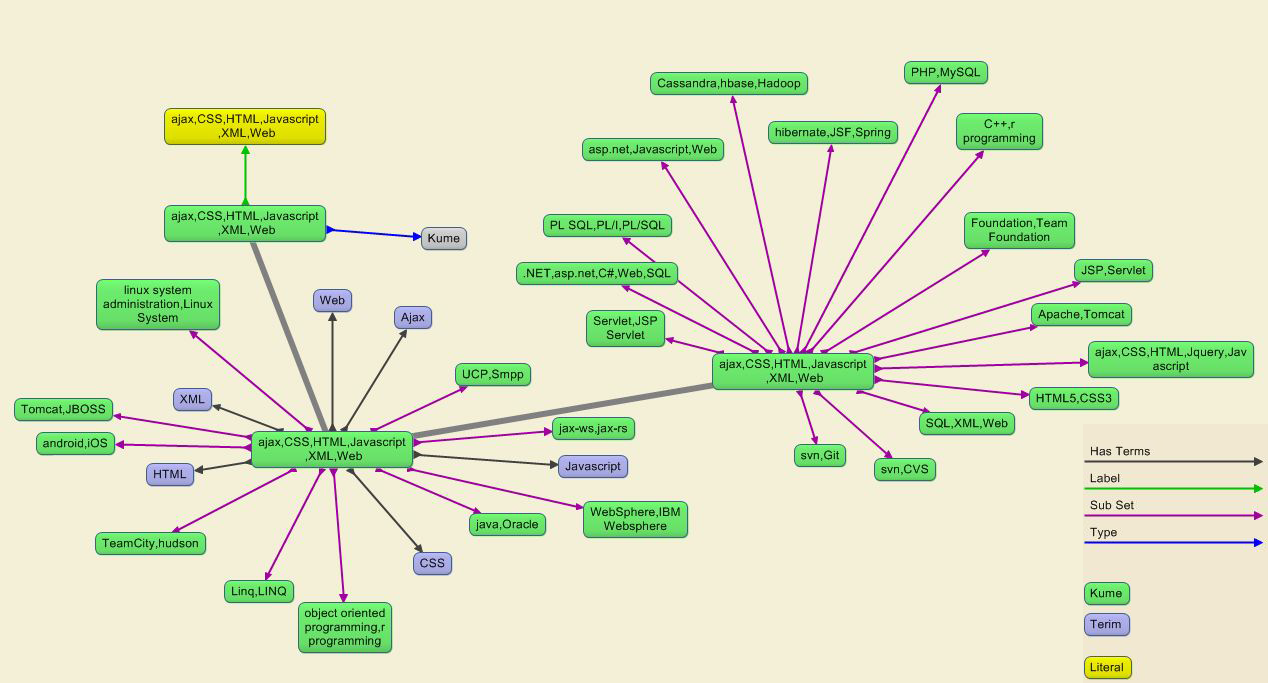
Sonuç
Test için, 30.000 Word formatında Türkçe yazılmış özgeçmişten %71 doğru bilgi çıkarımı elde ettik. 30.000 özgeçmişi sistemin taraması yaklaşık 10 saniye sürdü.
Çalışmamızın ilk aşaması olan iş ilanlarından ve özgeçmişlerden doğal dil işleme yöntemleri ile bilgi çıkarım işlemi tamamlanmış olup, iş ilanı ve özgeçmişlerin karşılaştırılması için çalışmalarımız devam etmektedir. Aynı zamanda yukarıda gördüğünüz semantik ilişkilerin diğer yüzlerce pozisyon için çıkarılmasına da devam edilmektedir.
Bu çalışma TÜBİTAK TEYDEP programı tarafından 3130841 proje numarası ile desteklenmiştir.
Ve Asıl Sonuç :)